crawl neko
该项目仍有一些遗留问题,需要修复和重构,但因为咕咕咕所以很久都没有处理,请勿用于生产环境
这是一个实际上是为了自用而诞生的轻量级爬虫框架,其理念在于:
帮你完成繁杂的规划,剩下的事情自己来做
首次尝试写这种东西,肯定十分 naive
适用情况
- 爬取较为少量的重点内容
- 需要高定制度的爬取
- 需要按层级爬取,并且在同一层级中需要做的事情基本相同
例如一个小说站,你需要依次爬取 分类列表->小说列表->章节列表->正文
安装
npm i crawl-neko工作流程
事件及函数队列
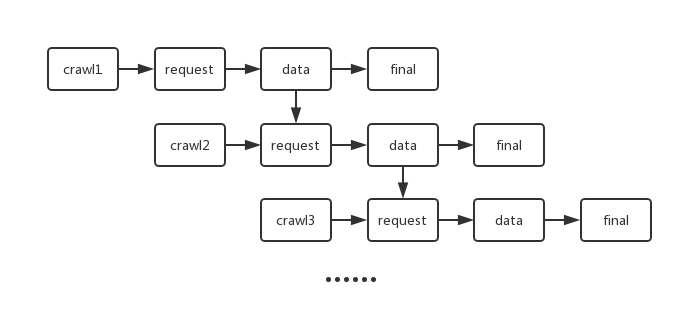
一共具有以下四个事件
- request
- 对“爬取目标”进行网络请求
- 函数得到的第一个参数为爬取目标
- 如果你向该爬虫添加了多个爬取目标,则爬虫会触发多次
request事件,每次只使用一个爬取目标作为首参数 - 如果不向该事件添加函数,则默认使用
axios的get方法进行请求;如果得到的内容是 JSON,则会被axios自动转换为对象;如果得到的内容是字符串,则交由cheerio解析并返回一个cheerio实例 - 如果向该事件添加函数,即相当于自定义你的请求方法,则必须返回自行进行网络请求后得到的内容
- data
- 对
request事件执行完毕后得到的结果进行处理,提取重点内容 - 函数得到的第一个参数为
request事件的函数队列的最终返回值,第二个参数为request的目标URL - 如果你使用
next()为当前爬虫指定了后继爬虫,则该data函数队列的最终返回值会作为后继爬虫的爬取目标
- 对
- final
- 对
data事件执行完毕得到的结果进行收尾处理,你可以在这里自由发挥 - 如果
data事件的函数队列最终返回了一个数组,则每次依次取其中一个元素作为final事件的参数来执行(与request那块同理) - 该函数队列最终可以不返回值
- 该函数队列可以最终返回一个具有固定结构的对象(或对象的数组)来作为该框架封装了的部分爬虫工具的参数(详见工具)
- 对
- error
- 特殊的事件,只有在出现异常错误时才会触发
- 函数的第一个参数为被抛出的
Error对象 - 该函数队列不需要最终返回一个值
工具
在final事件函数队列中,如最终返回具有固定结构的对象则可以使用以下功能
download
使用axios下载文件,例如以下返回对象示例会指使工具下载该 URL 的图片文件至项目目录下的dltest/test
type: "download" dir: "dltest" file: "test.png" url: "https://i.pximg.net/img-original/img/2015/05/25/12/40/22/50554350_p0.png" option: headers: referer: "https://www.pixiv.net/" { console; }type: 固定为downloaddir: 欲下载到的目录路径,可以为绝对或相对file: 欲下载文件的保存名url: 下载网址option: axios 参数,请参照此处callback: 下载完成后的回调函数,第一个参数即为该对象
使用
on(eve, func)
向事件添加函数到函数队列中,事件eve可取以下字符串
- request
- data
- final
- error
函数func可以是普通函数或是一个Promise,参数在事件及函数队列中有说明
setCheerioParameter(parameter)
当未设定request事件的响应函数时,默认会使用axios进行请求,并且如果取得的内容为 HTML,则会自动使用cheerio进行解析
此函数用于设置cheerio的解析参数,当不设置时,默认参数为
thischeerioParameter = decodeEntities: falsenext(crawl, inheritRequest = false)
设置该爬虫的后继爬虫
第一个参数为后继爬虫的对象,第二个参数为后继爬虫是否继承该爬虫的request事件
该继承包括request事件函数队列以及cheerio参数
async start(requestTargets)
开始爬行
requestTargets为爬取目标(URL),可以是string或者Array<string>
当然,如果你自定义了request事件的函数,则不必再限定为string,但若要传递多个目标仍需要使用Array
static isCrawlNeko(obj)
判断对象是不是 CrawlNeko 的 friends
static getTools()
取得工具集,以便于进行定制度更高的开发,其可用函数详见src/tools.js
一个例子
在test/index.js,你可以克隆源码后执行npm test来运行查看效果
const CrawlNeko = ;const Path = ; let catalog = ;let detail = ; // Get the detail link of nhentai comics (3 only for test)catalog; // And out put themcatalog; // Get the detail infomation from a linkdetail; // And output and download them (CAUTION: Adult content)detail; // Set 'detail' as the next crawl of 'catalog'catalognextdetail; catalogstart'https://nhentai.net/language/chinese/';TODO
- 增加对数据库操作的封装
- [-] 增加对文件下载操作的封装